Duplicate file finder
About
The duplicate finder is a tool that helps you identify likely duplicate files. Duplicate files are determined by file name, file type, and also two small checksums – one small checksum on the header and one small checksum on the body of the file.
Only one duplicate file search can happen at a time and can take several minutes. You may get a 503 error if multiple are attempted at the same time.
Limitations and considerations
Checksums
Because the application needs to check every single potential duplicate, this list can be large checksums needs to be performed to verify its a likely duplicate. Since checksums could be very CPU intensive, this feature is limited to one request at a time. Results are cached, so the same file won’t be re-processed again if searching over a short time.
Minimum Size
If there are many files to check, the process can take quite some time. Try starting a search with a larger value to find the biggest files first.
Timeouts
If you are running this behind a proxy or some system that will cause a time limit for api operations, you may see a timeout. Since results are cached, you should be able to search shortly after again and get results back more quickly.
Disabling the feature
With all of the above considerations, the duplicate finder does work very well. In future versions, if you do not wish users to be able to use this feature it will be disabled at a server level. But currently, theres no way to block the usage.
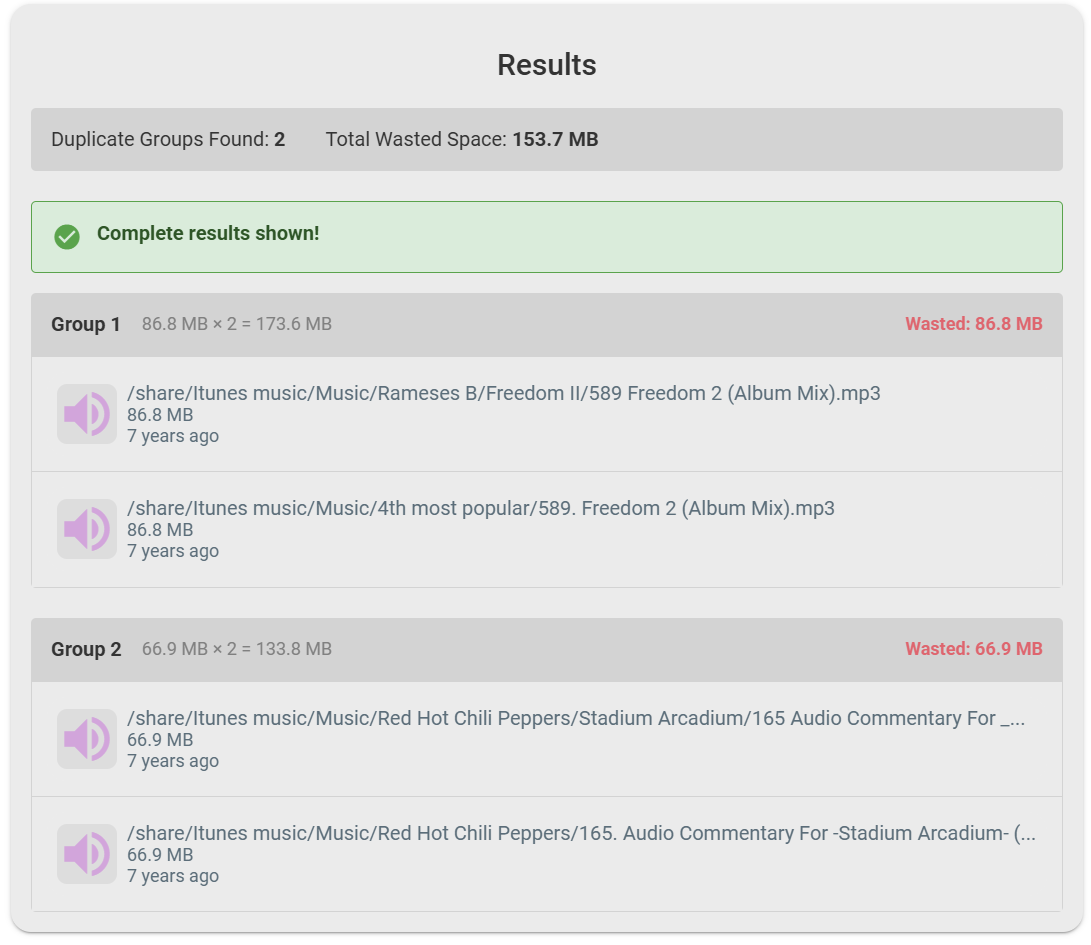
Example Usage
Here is an example duplicate file search: